NBDC-DDBJインピュテーションサーバ (beta)
インピュテーションサーバ(Imputation Server) は、SNPアレイデータのインピュテーション解析を支援��するサービスです。🔗ミシガン大学のインピュテーションサーバ や 🔗TOPMed プロジェクトのインピュテーションサーバ が公開されています。これらのサーバは日本国外に設置されており、利用のためにゲノムデータ(SNPアレイデータ)を国外のサーバにアップロードする必要がありました。
そこで、🔗国立研究開発法人科学技術振興機構 NBDC事業推進部 では日本の研究者が利用しやすい日本版インピュテーションサーバとして、NBDC-DDBJインピュテーションサーバのシステムを開発しました。現在このシステムは、国立遺伝学研究所スーパーコンピュータシステム の 個人ゲノム解析区画 で利用可能です。
本サーバで使用しているインピュテーションのワークフローは、以下のAMED事業において国立国際医療研究センターが検討した情報(インピュテーションソフトウェアの選定・パラメータの設定)の提供を受け、その情報を参考にNBDC事業推進部がウェブサービスとして改変・実装したものです。
事業名:ゲノム医療実現推進プラットフォーム事業(国際的データシェアリングに関する課題解決のための調査研究及び開発研究)
課題名:「クラウド計算環境を利用したゲノム医科学研究の倫理・技術課題の調査と実践」
NBDC-DDBJインピュテーションサーバ(ベータ版)の概要
NBDC-DDBJインピュテーションサーバ(ベータ版)(以下、本システム)は、遺伝研スパコンの個人ゲノム解析区画で利用可能です。研究者(利用者)はご自身のゲノムデータをサーバにアップロードし、Webユーザインターフェースを介してインピュテーション解析ワークフローを実行することができます。ワークフローの計算が完了した後に、計算結果であるインピュテーションされたゲノムデータをダウンロードすることができます。通信を暗号化したバーチャルプライベートネットワーク(SSL-VPN)を用いることで、本システムをセキュアに利用することが可能です。
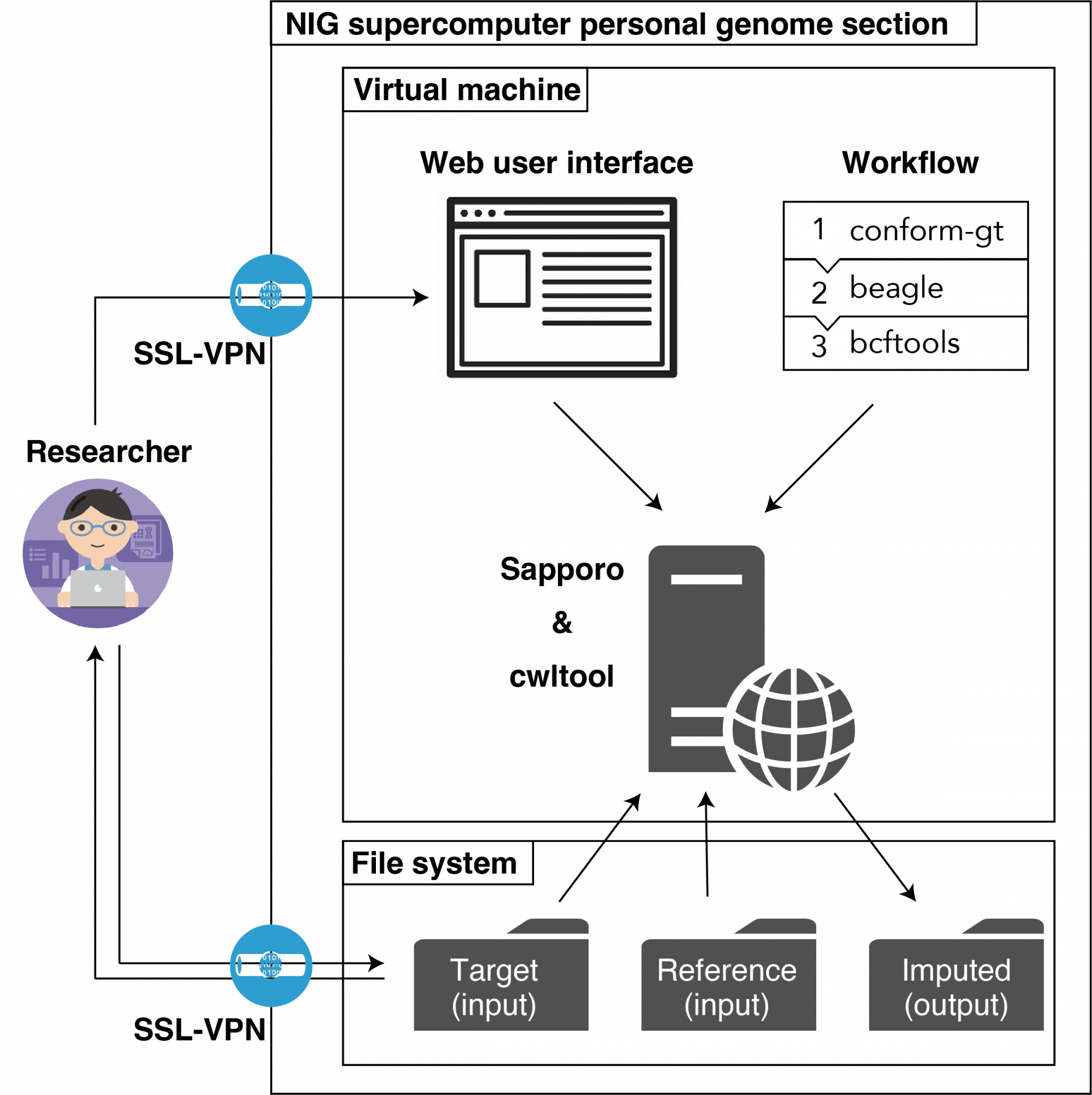
NBDC-DDBJインピュテーションサーバのシステム構成図 研究者のイラストは TogoTV (©2016 DBCLS TogoTV / CC-BY-4.0) によって作成されたものを用いました。
利用可能なインピュテーションアルゴリズム
本システムでは、以下のプログラムを用いてインピュテーション解析を行います。
- 🔗conform-gt (version 24May16) を用いて、入力となる SNP アレイデータの reference / alternative allele がリファレンスパネルデータと一致するように変換します
- 🔗Beagle 5.2 (version 21Apr21.304) を用いてフェージングおよびインピュテーション解析を実施します
- 🔗bcftools (version 1.9) を用いてインピュテーション後のゲノムデータ(VCF file)のインデックスを作成します
一連のワークフローは 🔗Common Workflow Language (CWL) で実装され、🔗imputation-server workflow として公開されています。
主な入力ファイル
インピュテーションワークフローの入力となるのは次の2つのデータセットです。
- Target genotype dataset: SNPマイクロアレイでジェノタイプされたデータセットです。ご自身でサーバにアップロードいただくことを想定しています。ファイル形式はVCFをサポート��しています。(PLINK形式は現在サポートしていません)
- Reference panel dataset: フェーズされたハプロタイプを含むデータセットです。すぐに利用可能なリファレンスパネルが6種類用意されています。
主な出力ファイル
- Imputed genotype dataset: インピュテーション後のジェノタイプデータセットです。ファイル形式は VCF です。インピュテーション結果である allele dosage データは、DS tag に出力されます。推定アリル頻度 (estimated allele frequency) とインピュテーション品質 (dosage R2) は INFO カラムに出力されます。
利用可能なリファレンスパネルの種類
本システムでは、現在6種類のリファレンスパネルが利用可能です。非制限公開データのリファレンスパネル利用には、データ利用申請の必要はありません。制限公開データのリファレンスパネルを利用いただくためには、リファレンスパネルデータのNBDCへのデータ利用申請 が必要です。
| リファレンスパネルの名前 | 概要 | アクセスレベル | アセンブリバージョン |
|---|---|---|---|
| GRCh37.1KGP | 🔗The 1000 Genomes Project のリファレンスパネルです。複数のancestryに属する 2,504 名のサンプルを含みます | 非制限公開 | hg19, GRCh37 |
| GRCh37.1KGP_EAS | 🔗The 1000 Genomes Project のリファレンスパネルです。東アジアancestryに属する 504 名のサンプルを含みます | 非制限公開 | hg19, GRCh37 |
| GRCh38.1KGP | 🔗The 1000 Genomes Project のリファレンスパネルです。複数のancestryに属する 2,548 名のサンプルを含みます | 非制限公開 | GRCh38 |
| GRCh38.1KGP_EAS | 🔗The 1000 Genomes Project のリファレンスパネルです。東アジアancestryに属する 508 名のサンプルを含みます | 非制限公開 | GRCh38 |
| BBJ1K+GRCh37.1KGP | 🔗BioBank Japanプロジェクトのリファレンスパネルと🔗The 1000 Genomes Project のリファレンスパネルをクロスインピュテーションして得られたリファレンスパネルです。BioBank Japanプロジェクトの 1,037名のサンプルと、10000 Genomes Project の複数の ancestryに属する 2,504 名のサンプル(合計 3,541名)を含みます | 制限公開 | hg19, GRCh37 |
| BBJ1K+GRCh37.1KGP_EAS | 🔗BioBank Japanプロジェクトのリ�ファレンスパネルと🔗The 1000 Genomes Project のリファレンスパネルをクロスインピュテーションして得られたリファレンスパネルです。BioBank Japanプロジェクトの 1,037名のサンプルと、10000 Genomes Project の東アジアancestryに属する 504 名のサンプル(合計 1,541名)を含みます | 制限公開 | hg19, GRCh37 |
リファレンスパネルごとのインピュテーション精度を比較した結果、制限公開データである BBJ1K+GRCh37.1KGP reference panel の精度が最も高いと評価されました。詳細は🔗本システムの論文をご参照ください。
本システムを利用して論文を作成する際のお願い
- 本システムの論文を引用してください。
- 遺伝研スパコンの利用について謝辞などにてご記載ください(記載文例)。
- 制限公開データを利用された際には、使用したデータセットのアクセッショ��ン番号を記載してください。また、当該データセットについて報告された論文(当該データセットのデータ提供者等が当該データセットを根拠データとして作成した論文)の引用、もしくは謝辞(Acknowledgement)として🔗記載文例の内容を記述して下さい。
NBDC-DDBJインピュテーションサーバ(ベータ版)の利用方法
本システムは、個人ゲノム解析区画のユーザを対象としています。個人ゲノム解析区画の利用申込については、個人ゲノム解析区画のアカウントの新規登録から利用開始までの流れ をご参照ください。個人ゲノム解析区画のユーザは、次の手順で本システムをご利用いただけます。本システムを利用する場合1ユーザにつき1つのguacamoleを利用した仮想環境をしようすることを強く推奨いたします。
- 本システム利用申請窓口(imputation-server@ddbj.nig.ac.jp)に、利用申込メールを送ってください
- スパコン管理者が計算ノードの一部を切り出し本システムのバーチャルマシンを起動します。また、リモートデスクトップ環境利用マニュアルを送付します。
- リモートデスクトップ環境利用マニュアルに従って、リモートデスクトップ環境にログインしてください
- NBDC-DDBJインピュテーションサーバ(ベータ版)インストールマニュアル に従って、セットアップを行なってください
- NBDC-DDBJインピュテーションサーバ(ベータ版)チュートリアル1、公開レファレンスパネルを使う場合 に従って、公開されているゲノムデータとリファレンスデータを用いて、インピュテーションサーバの利用方法を習得してください
- 以上のステップを完了すると、ご自身のゲノムデータ(SNPアレイデータ)をアップロードした後、インピュテーション解析の実施、および、インピュテーション解析結果のダウンロードを行うことができます
- 制限公開データを利用される場合は NBDC-DDBJインピュテーションサーバ(ベータ版)チュートリアル2、制限公開レファレンスパネルを使う場合 を参照ください。
NBDC-DDBJインピュテーションサーバ(ベータ版)の利用を希望します。
新たにguacamoleを利用した仮想マシン環境の構築をお願いできますと幸いです。
個人ゲノム解析区画のアカウント名: ________ (例:youraccount-pg)
guacamoleを起動するマシン名: ________ (例:at001)
コア数: ______ (推奨: 16以上)
RAM: ______ (推奨: 128GB以上)
マウントするディレクトリ: __________ (例: /home/ddbjshare-pg [必須], /home/youraccount-pg [必須])
その他: singularityのインストールもお願いいたします。
どうぞよろしくお願いいたします。
制限公開データのデータ利用申請
制限公開リファレンスパネルは Japanese Genotype-phenotype Archive (JGA) に登録されています。JGAデータの利用申請方法は 🔗NBDCヒトデータベース データの利用 をご参照ください。申請時に必要となるアクセッションcode は次表を参照してください。
| リファレンスパネルの名前 | リサーチID | データセットID |
|---|---|---|
| BBJ1K+GRCh37.1KGP | hum0014 | JGAD000679 |
| BBJ1K+GRCh37.1KGP_EAS | hum0014 | JGAD000679 |
問合せ窓口
本システムに関する問合せは imputation-server@ddbj.nig.ac.jp にご連絡ください。