ベンチマーク(NVIDIA Parabricks)
概要
本ページでは、NVIDIA Parabricks (以降 Parabricks と呼ぶ) というゲノム解析ツールの性能を、最新の NVIDIA H100 SXM 80GB GPU を 8 基搭載したハードウェア環境で詳細に検証した結果を掲載する。 我々の実験では、臨床研究で用いられる典型的な全ゲノムシークエンスデータセットを使用し、計算時間と出力結果の妥当性を評価した。 その結果、NVIDIA H100 GPU を搭載したシステムでは、従来の V100 を搭載したシステムと比べて計算速度を 2.3 倍以上高速化できると示された。
検証GPU環境
アプ�リケーションの実効性能比較のために、H100 搭載ノードの他に V100 搭載ノードも用いて性能評価を行った。 検証対象の H100 搭載ノードは、さくらインターネットが提供する高火力 PHY のベアメタルサーバ (以降 高火力 PHY) で実行され、V100 搭載ノードは、遺伝研スーパーコンピュータシステムが提供する Thin 計算ノード (Type 2b) (以降 遺伝研 igt) で実行した。 いずれも、単体のノードとして使用され、複数台のノード構成によるアプリケーション性能評価は行っていない。 この二つの異なる環境下で運用されるノード間で、GPU 関連ドライバー等のバージョン違いなどに起因する実行性能への影響を防ぐ目的で、これまで対象アプリケーションの実行実績のある遺伝研 igt の環境設定を検証条件として採用し、高火力 PHY 上での環境構築を行った。 検証に利用した遺伝研 igt と高火力 PHY の GPU ノードのハードウェア環境およびソフトウェア環境を表1に示す。
表 1 検証ノード構成
| 遺伝研igt | 高火力PHY | |
|---|---|---|
| ハードウェア構成 | ||
| CPU (総コア数) | Intel Xeon Gold 6136 3.0GHz x 2基 (24) | Intel Xeon Platinum 8480 2.0GHz x 2基 (112) |
| メモリー | DDR4 384GB | DDR5 2.0TB |
| GPU (FP64) | NVIDIA V100 SXM2 16GB (7.8 TFlops) x 4基 | NVIDIA H100 SXM5 80GB (33.5 Tflops ) x 8基 |
| GPU間接続 | NVLink Hybid Cube Mesh | NVSwitch Fabric |
| システムディスク | NVMe SSD 1.6TB x 1枚 | NVMe SSD 960GB x 2枚 (RAID1構成) |
| データディスク | NVMe SSD 3.2TB x 1枚 | NVMe 7.68TB x 4枚 |
| ソフトウェア構成 | ||
| OS | Ubuntu Server 22.04 LTS | Ubuntu Server 22.04 LTS |
| GPUドライバー | 530.30.02 | 530.30.02 |
| CUDA | 12.1 | 12.1 |
| Fabric Manager | N/A | UP |
| Singularity CE | 4.0.0 | 4.0.0 |
ハードウェア構成
基本構成の違いとして、遺伝研 igt では 24 コアを持つ CPU に DDR4 の 384GB のメモリを採用しているのに対して、高火力 PHY では、112 コアに、2TB のメモリと強化されている。 加えて GPU に関しては、遺伝研 igt では、Volta GV100 アーキテクチャを採用した V100 SXM2 16GB をノード内に 4 枚収容し、NVLink Hybid Cube Mesh で GPU 間が相互に接続した構成に対して、高火力 PHY では、Hopper GH100 アーキテクチャを採用した H100 SXM5 80GB をノード内に 8 枚収容し、NVSwitch により 8 基の GPU 間を相互に高速接続している。
ソフトウェア構成
検証環境で構成される OS のディストリビューション、GPU を利用する際に不可欠なドライバー、管理ツール等 のソフトウェアスタックを、遺伝研 igt と高火力 PHY において可能な限り一致させる事で、対象とするアプリケーションの実装上の違い以外の差異を最小限に抑えた。 性能評価対象の高火力 PHY がベアメタルサーバであるのに対して、遺伝研 igt はマネージドクラスターでもあり、容易に OS 等と密接に関連したドライバーの変更はマネージドクラスターの運用に関わる事でもあるため、比較的柔軟に対応できるベアメタルサーバである高火力 PHY 側を遺伝研 igt のソフトウェア構成に合わせた。ソフトウェアの実行には実際の分野研究で使われているワークフロー環境での実績を重視して、Singularity コンテナのプラットフォーム上での評価環境を構築した。
ストレージ環境
Parabricks の実行には、十分なサイズのデータセットを格納でき、高速に読み書きできるストレージ環境の確保は不可欠である。 遺伝研 igt および高火力 PHY は、高速な NVMe SSD をローカルストレージとして備えている事から、各アプリケーションの入出力用のストレージ領域として利用した。 検証に利用した遺伝研 igt と高火力 PHY の搭載されているストレージ構成と、fio コマンドによるファイルのシーケンシャルな READ/WRITE による I/O 性能測定結果を表2に示す。 測定対象にある/tmp は、システムディスク上の NVMe SSD を指している。 遺伝研 igt では/data ��領域での性能に差は少なかった。 一方で、高火力 PHY では約 7 倍の性能差があった。
表 2 検証環境のストレージ構成とシーケンシャル I/O 性能
| 測定対象 | READ | WRITE | |
|---|---|---|---|
| 遺伝研igt | /tmp | 533MiB/s | 531MiB/s |
| /data | 607MiB/s | 605MiB/s | |
| 高火力PHY | /tmp | 145MiB/s | 153MiB/s |
| /data | 1052MiB/s | 1111MiB/s |
ゲノム解析ソフトウェア
NCGM WGSpipeline は、ヒト個人の全ゲノムシークエンス (whole-genome sequencing; WGS) データを入力として多型検出を行う汎用的なワークフローである。このワークフローは、複数のコンポーネントから構成されており、参照ゲノム配列へのマッピング、マップされた配列から多型を検出するバリアントコールなどのプロセスが含まれている。 NCGM WGSpipeline は、GPU を活用する NVIDIA 社の Parabricks を主なゲノム解析ソフトウェアとして利用しており、従来の CPU ベースの Genome Analysis Toolkit (GATK) をゲノム解析ソフトウェアとして利用する場合と比較して、10 倍以上高�速にデータ加工を実施することができる。FPGA を用いたアクセラレータを利用する手法も提案されているが、Parabricks の利点のひとつは、汎用の GPU を使用できるため計算機資源をより柔軟に活用できる面にある。ワークフローの可搬性と可用性を高めるため NCGM WGSpipeline は Common Workflow Language (CWL) を用いて実装されており、異なる計算機環境であっても容易に実行が可能である。
性能評価
性能評価では高火力 PHY および遺伝研 igt 上で、以下のバージョンの Parabricks ソフトウェアを用いた NCGM WGSpipeline で解析を行った。
- v4.1.0
- v4.1.1
- v4.2.0
- v4.2.1
実行パラメータとして、GPU RAM の使用量を抑える ‘–low-memory’ オプションを指定した場合と指定しない場合の両方について計算時間を評価した。 入力として 1000 人ゲノムプロジェクトから 20 サンプ ル (NA18941、NA18945、 NA18946、 NA18952、 NA18953、 NA18957、 NA18960、 NA18964、 NA18969、 NA18971、 NA18972、 NA18976、 NA18983、 NA18988、 NA18990、 NA18991、 NA18995、NA19001、 NA19002、 NA19006) を選択して解析を行なった。 Parabricks v4.2.0 および v4.2.1 において 2 サンプル (NA18941、 NA18995) は実行エラーが生じ計算速度測定を行えなかった。 そのため、18 サンプル の計算時間の平均を比較した。 各サンプルの入力データは 20 個程度の圧縮済 fastq ファイルに分割収容されており、各サンプルにおける入力データの総データ量は圧縮下で約 43GB から 55GB であった。
ノードおよびバージョンごとの解析時間
表3にノードおよび Parabricks のバージョンごとの解析時間を示す。 今回の性能評価では、同一ノード上であれば Parabricks のバージョンで解析時間はほとんど変わらなかった。 また遺伝研 igt では GPU RAM 容量が 16GB であり ‘–low-memory’ オプション無しでは実行できないことが分かっていたため ‘–low-memory’ オプション有りでのみ実行した。 ‘–low-memory’ オプション有りの結果を比較すると、いずれのバージョンでも、高火力 PHY は遺伝研 igt の 2.3 倍以上高速に解析を完了できた。 解析が高速だった要因として GPU の性能や GPU の搭載数の差が考えられるが、どの要素が支配的かは今回の評価では判断できなかった。 また高火力 PHY のいずれのバージョンでも、‘–low-memory’ オプションの有無で解析速度にほとんど差は出なかった。
表 3 ノードおよび Parabricks バージョンごとの解析時間
| GPU | Parabricks version | 解析時間(分)w/ low memory | 解析時間(分)w/o low memory |
|---|---|---|---|
| 高火力 PHY | v4.1.0 | 37.65 | 38.42 |
| (H100x8) | v4.1.1 | 38.15 | 37.93 |
| v4.2.0 | 36.17 | 36.78 | |
| v4.2.1 | 37.87 | 36.38 | |
| 遺伝研 igt | v4.1.0 | 88.00 | - |
| (V100x4) | v4.1.1 | 88.42 | - |
| v4.2.0 | 89.13 | - | |
| v4.2.1 | 90.05 | - |
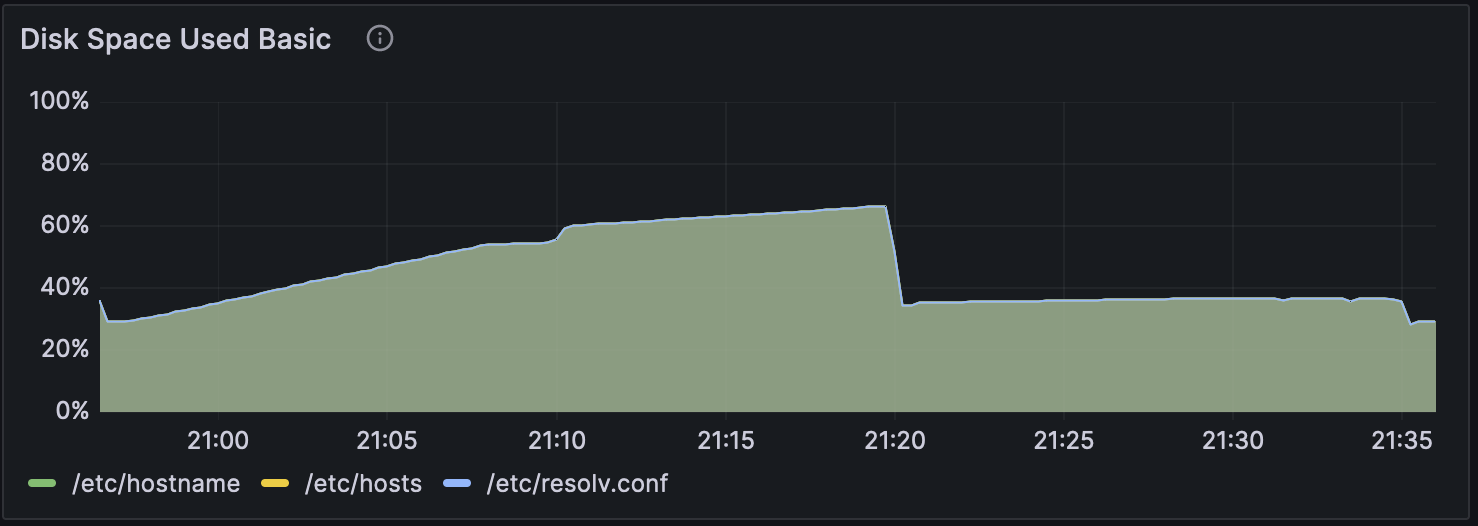
また、高火力 PHY での Parabricks v4.2.1 のでの ‘–low-memory’ オプション有りでのGPU使用率の推移を図1に、CPU使用率の推移を図2に、ディスク使用率の推移を図3に示した。 解析開始から 21:10 頃まではマッピング処理、 21:21 以降はバリアンとコール時の推移を表している。 マッピング処理時では GPU を効率的に使えていないことがわかるが、これはマッピング処理およびその後処理でファイルの圧縮および書き込みを並行して行っているのが理由だと考えられる。 またマッピングおよびその後処理では CPU コアを一部しか使えていないことがわかるが、これがアルゴリズム的な制約なのか、実装やオプション設定の問題なのかは今後調査が必要である。 NCGM WGSpipeline では合計 5 種類のバリアントコールが実行される。 21:21 か��ら 21:30 までは常染色体に対するバリアントコールで、他のバリアントコールよりも時間がかかっていることがわかる。 その他のバリアントコールはすべて一分以内に終了しており、解析全体と比較すると時間がほとんどかかっていないこともわかる。 またバリアントコール時に GPU および CPU 使用率が特定の値から増加していないように見えることから、GPU および CPU コアを一部しか使えていない可能性がある。
図 1 高火力 PHY 環境上で Parabricks 解析時の GPU 使用率
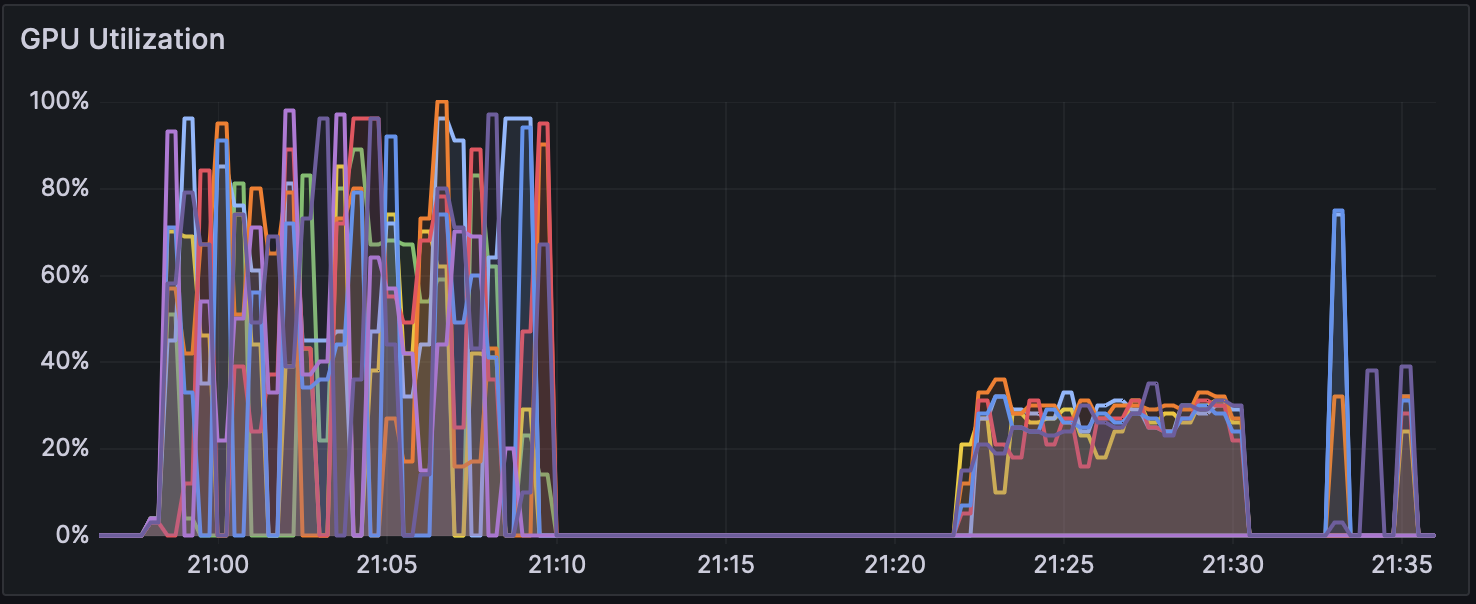
図 2 高火力 PHY 環境上で Parabricks 解析時の CPU 使用率
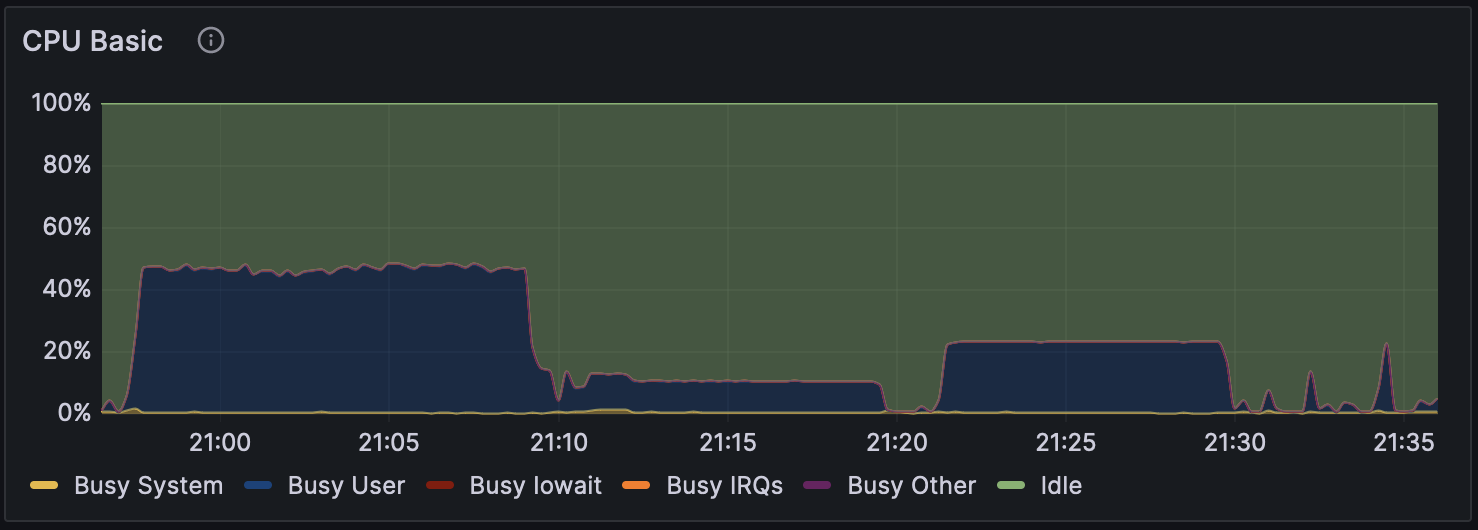
図 3 高火力 PHY 環境上で Parabricks 解析時のディスク使用率
解析結果の妥当性
表4に Parabricks v4.0.0 と今回評価した各バージョンの Parabricks の計算結果の多型検出結果の一致率 (genotype concordance) を示す。 一致率は多型の種類を考慮し SNP(一塩基置換) と INDEL(塩基配列の挿入・欠失) を区別して計算した。 多型の種類にかかわらず、v4.1.0 および v4.1.1 の解析結果は v4.0.0 と完全に一致した。 v4.2.0 および v4.2.1 では v4.0.0 の解析結果と完全一致ではないものの、非常に高い一致率を示しほとんど完全に一致していた。 v4.0.0、 v4.1.0、 v4.1.1 は GATK v4.2.0.0 と互換となるよう実装されており、v4.2.0、 v4.2.1 は GATK v4.3.0.0 と互換になるよう実装されている。 この点が Parabricks v4.2.0 および v4.2.1 の結果が v4.0.0 と完全一致しなかった原因と考えられる。 全てのバージョンにおいて解析結果は Parabricks v4.0.0 の結果と非常に高い一致率を示し、解析結果は妥当だと考えられる。
表 4 Parabricks v4.0.0 と評価に用いたParabricksバージョンごとの変異種類ごとのgenotype concordance
| v4.1.0 | v4.1.1 | v4.2.0 | v4.2.1 | |
|---|---|---|---|---|
| SNP | 1.0000000 | 1.0000000 | 0.9999979 | 0.9999979 |
| INDEL | 1.0000000 | 1.0000000 | 0.9999932 | 0.9999932 |
本記事について
本成果は、国立遺伝学研究所DDBJセンターと、さくらインターネット株式会社との間で実施の共同研究「大規模研究データのライフサイクルデザインに関する研究(2020年度〜)」の一環で2023年度に測定された結果を元に作成されました。
記事詳細・関連リンク
記事作成日:2024/5/28
プロジェクトメンバー
- 丹生 智也1、 2
- 野川 駿3
- 山本 謙太郎3
- 石井 学3
- 大田 達郎1、 4
- 小西 史一5
- 八谷 剛史3
- 小笠原 理1
1: 国立遺伝学研究所 生命情報・DDBJセンター
2: データサイエンス共同利用基盤施設 バイオデータ研究拠点
3: 株式会社ゲノムア��ナリティクスジャパン
4: 千葉大学 国際高等研究基幹
5: さくらインターネット株式会社